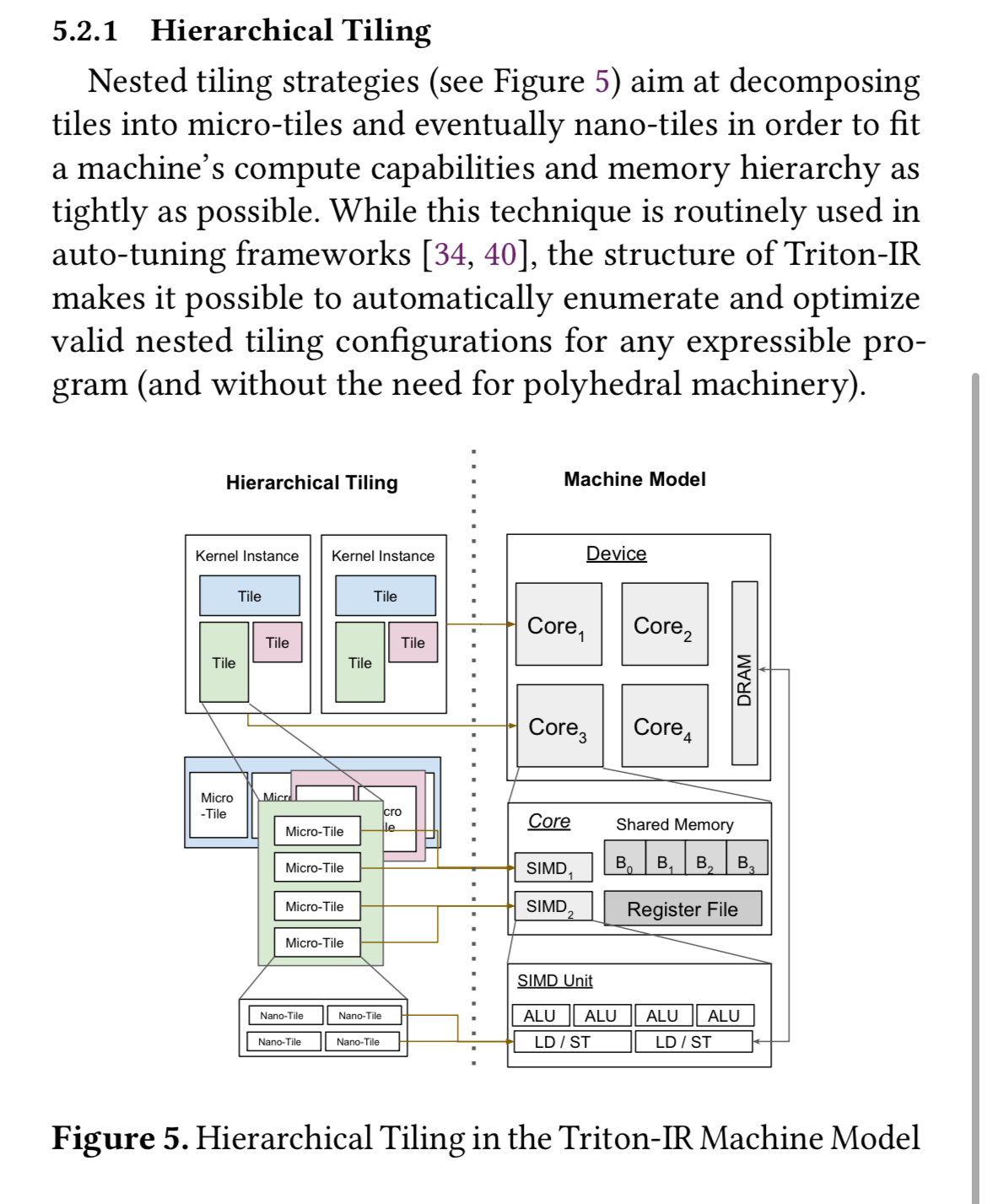
2025-01-15T10:17
A product of the hazy-research-and-flash-attention lab is ThunderKittens. In their README, they write (emphasis mine):
ThunderKittens is built from the hardware up -- we do what the silicon tells us. And modern GPUs tell us that they want to work with fairly small tiles of data. A GPU is not really a 1000x1000 matrix multiply machine (even if it is often used as such); it’s a manycore processor where each core can efficiently run ~16x16 matrix multiplies. Consequently, ThunderKittens is built around manipulating tiles of data no smaller than 16x16 values.
This reminds me a lot of this issue I filed in Cubed comparing Triton tiles and Zarr chunks: https://github.com/cubed-dev/cubed/issues/490